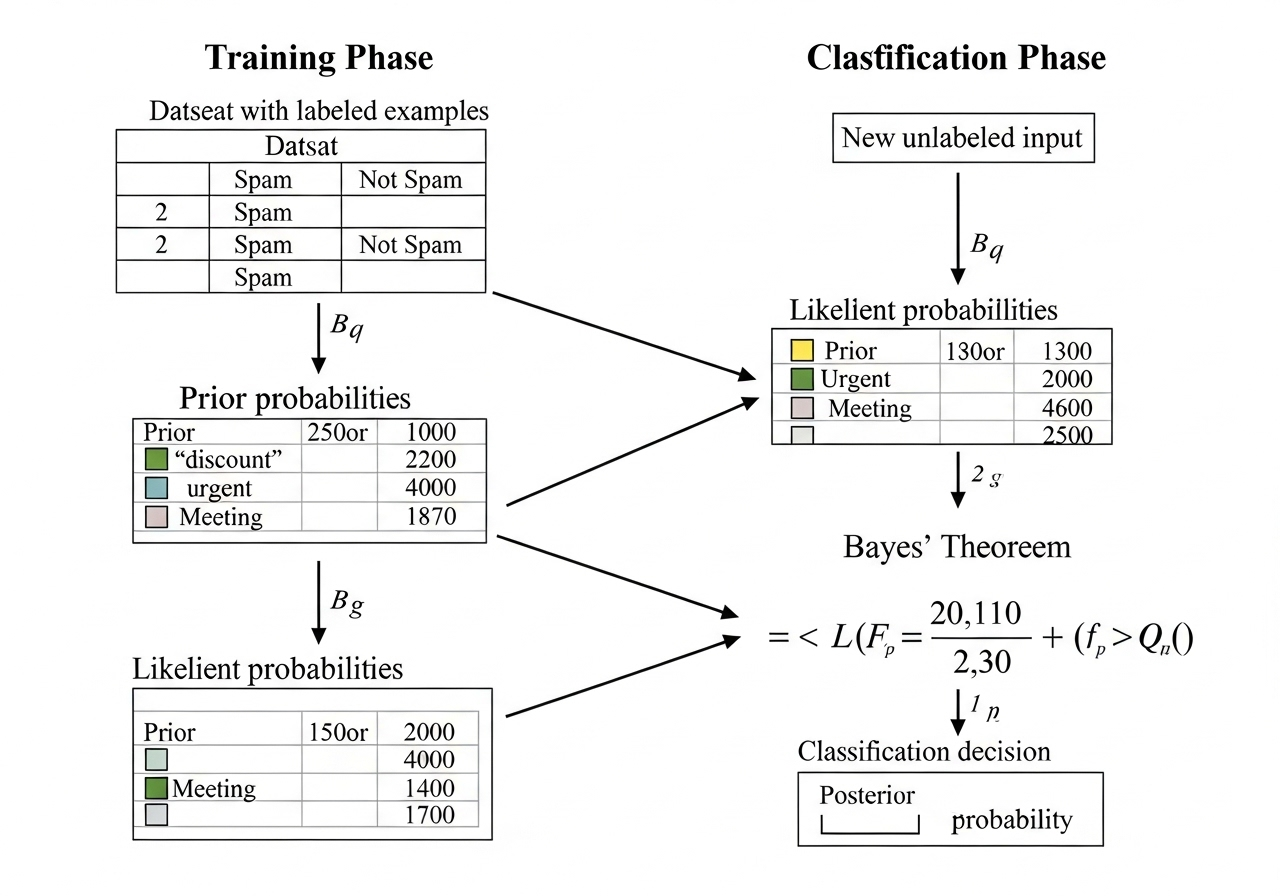
朴素贝叶斯分类
朴素贝叶斯分类贝叶斯分类是一类分类算法的总称,这类算法以贝叶斯定理为基础。而朴素贝叶斯分类是贝叶斯分类中最简单与常见的一种分类方法,它与贝叶斯分类的区别点是加了一个前提假设:所有的条件对结果都是独立发生作用的,即所有的特征之间相互独立。(比如某人是篮球运动员与某人有运动天赋,这两个特征之间是有关联的,不能算作完全独立。而特征有关联性会导致朴素贝叶斯概率误差较大) 贝叶斯公式 先验概率(Prior Probability):P(A)基于过去的经验认知,对某个事件发生概率的初步估计。后验概率(Posterior Probability):P(A|B)表示在特征B已知的情况下,类别A发生的概率。后验概率是基于先验概率和新的证据,通过贝叶斯定理修正后的概率。 在实际情况中,我们利用贝叶斯算法去判断类别时,往往是基于多个特征,极大似然估计MLE是朴素贝叶斯分类模型的简化版,在计算出先验概率和条件概率之后,直接将两者对应乘积。下图中x表示特征,等式表示n个特征情况下是c类别的概率,即条件概率P(B|A)。 当特征数据离散时如何求概率:需要处理数据1.数据离散化:等宽法,等频法,聚类法等。2...

模型微调
模型微调大模型微调是指在预训练的大型语言模型(如GPT-3、BERT)基础上,通过特定领域或任务的数据进行二次训练,使模型适应具体需求的技术。预训练模型已具备通用语言理解能力,微调通过调整模型参数,使其在特定任务(如医疗诊断、法律文本分析)中表现更优,同时保留原有知识。就像是让一个通才学霸转行为专科专家。 微调的原理微调的核心是参数调整:预训练模型通过海量数据学习通用规律(如语法、逻辑),参数已初步稳定。微调时,用特定领域数据重新计算损失函数(衡量模型输出与预期差距),反向传播更新部分或全部参数,使模型更贴合新任务。高效微调技术(如LoRA、P-Tuning)通过冻结大部分参数、仅训练少量适配层,降低计算成本。 模型微调实践案例金融情感分析:银行微调模型分析客户评论,识别负面情绪以优化服务,准确率提升30%。医疗诊断助手:某医院微调模型读取CT报告,生成诊断建议,减少医生工作量。中国通信院案例:涵盖工业、能源等领域,如某电力公司微调模型预测设备故障,降低维护成本。 总结大模型微调是让通用AI快速转行的技术。原理上,它基于预训练模型的知识底子,用少量数据调整参数,变成专业工具。实践...
模型蒸馏
模型蒸馏 Knowledge Distillation模型蒸馏是一种将大型模型(教师模型)的知识迁移到小型模型(学生模型)的技术,旨在让小模型在保持性能的同时降低计算资源消耗。其核心是通过对齐两者的输出分布(如概率或特征),使学生模型模仿教师模型的决策逻辑。根据实现方式,分为黑盒蒸馏(仅利用教师模型的输出结果)和白盒蒸馏(额外利用中间层信息)。 蒸馏原理蒸馏的底层逻辑是知识迁移。教师模型的输出(如分类概率)包含隐式知识(软目标),通过损失函数(如KL散度)驱动学生模型的输出与之对齐。同时,学生模型的结构可能被简化或调整,以适配资源限制。例如,白盒蒸馏会利用中间层的特征相似性,而黑盒蒸馏仅依赖最终预测结果。 模型蒸馏实践案例Qwen2.5系列:通过白盒蒸馏实现,利用前向KL散度对齐教师和学生模型的输出,代码开源且效果接近原模型。Deekseek R1:蒸馏过的小模型(8B参数的Deepseek-R1-Distill)在医疗领域微调,性能媲美大模型,且部署成本降低90%。OpenAI实践:通过蒸馏将500B参数模型压缩到100B,训练时间从1个月缩短至1周,大幅降低成本。 总结模型蒸...
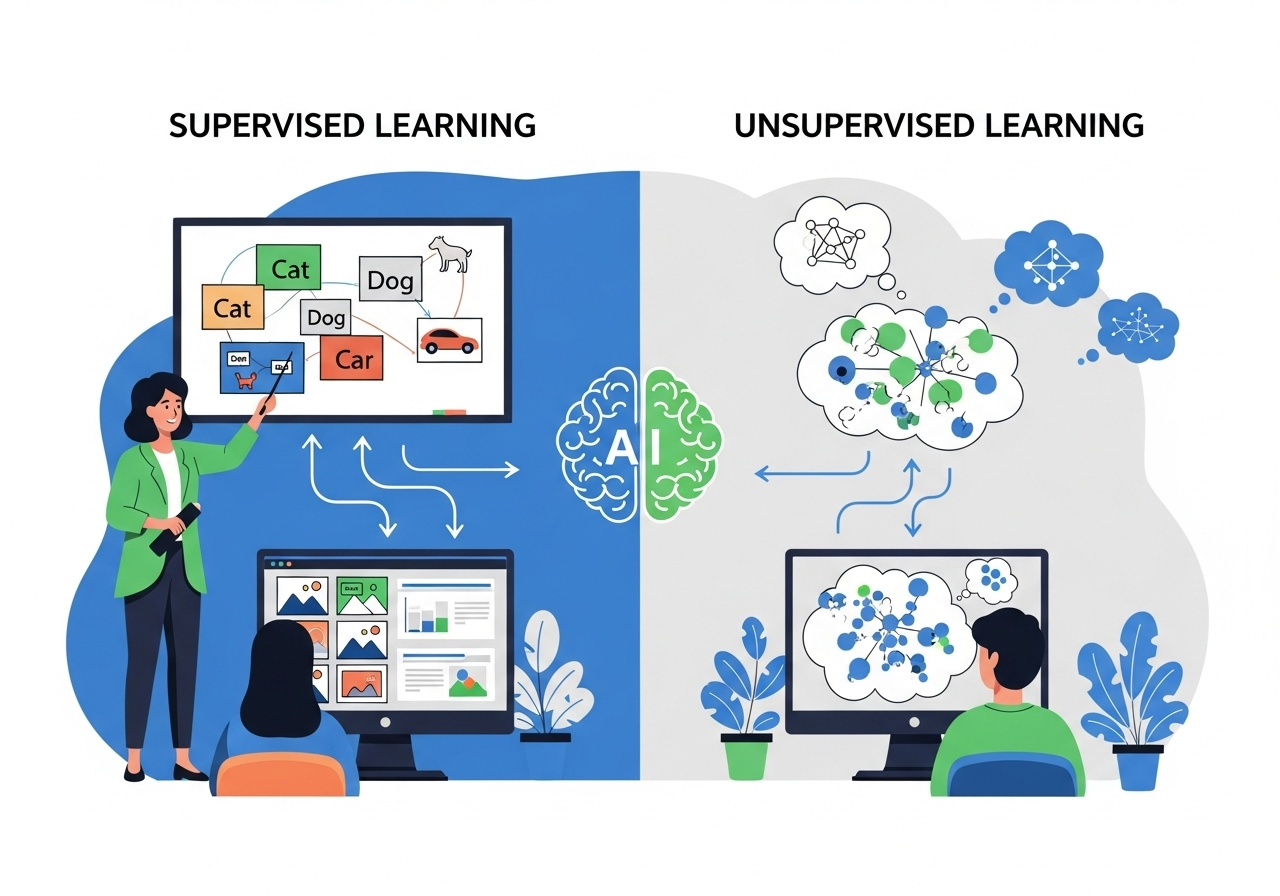
监督学习与无监督学习机制
1.1 监督学习 Supervised Learning训练数据: 有明确标签(数据集的每个样本的多种特征均有标准答案)输出: 有特定结果导向 回归算法regression与分类算法classification均属于监督学习机制,其他函数如支持向量机也属于该机制。 回归通过设计的算法输出连续值continuous value,分类输出离散值 discrete value。 1.2 无监督学习 Unsupervised Learning训练数据:无标签或均为同标签 (无标准答案)输出: 无特定结果导向,需要设计算法自行发现数据的规律。 聚类算法是无监督学习机制中的一种算法,其他函数如奇异值分解也属于该机制。
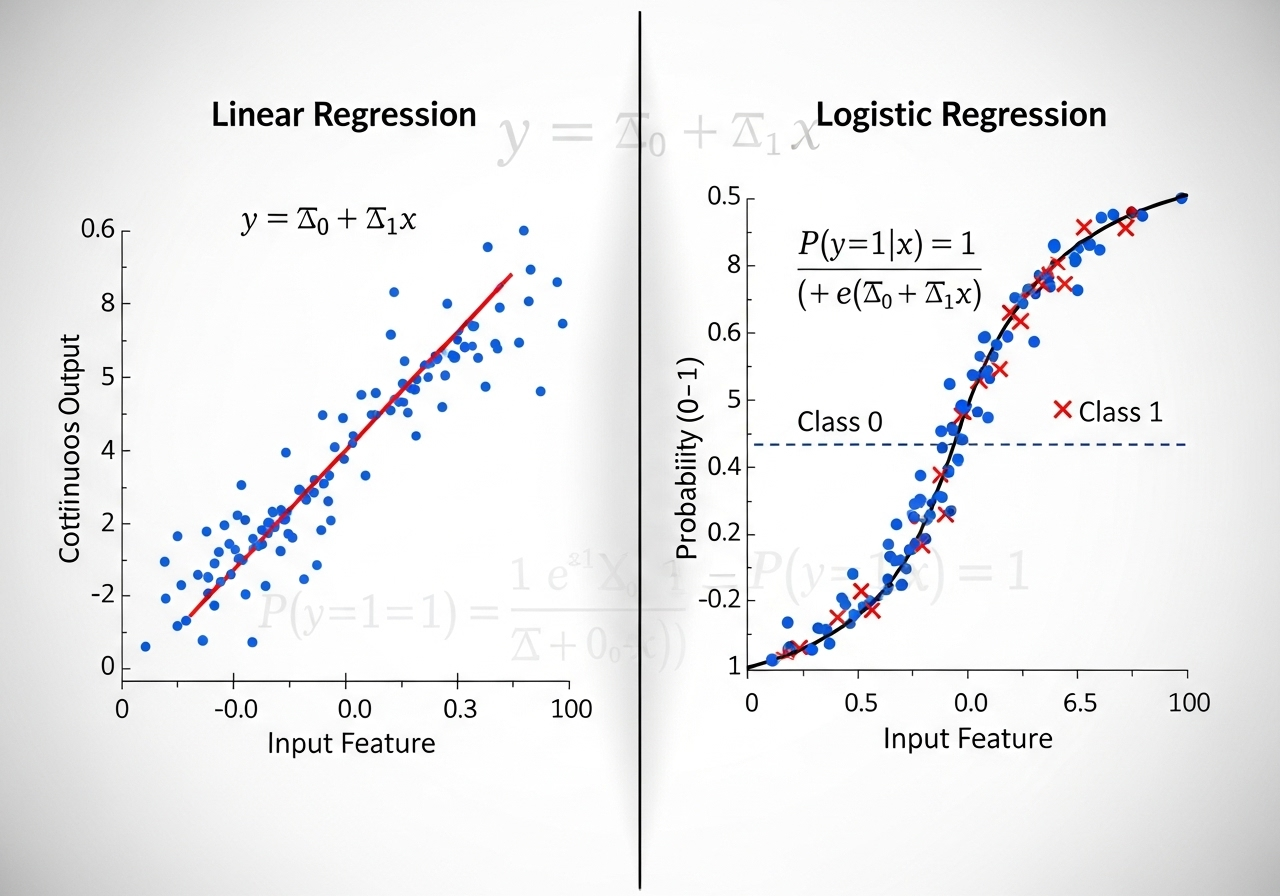
线性回归与逻辑回归
线性回归(Linear Regression)线性回归是一种监督学习算法,用于建立连续型变量(因变量)与一个或多个自变量之间的线性关系模型。核心思想:通过拟合最佳直线(或超平面)最小化预测值与真实值的误差。 数学模型 其中斜率系数代表权重参数。 损失函数损失是一个数值指标,用于描述模型的预测有多大偏差。损失函数用于衡量模型预测与实际标签之间的距离。训练模型的目标是尽可能降低损失,将其降至最低值。 损失类型: 使用不同损失函数训练出的模型,与离群值距离不同。 MSE:模型更接近离群值,但与大多数其他数据点的距离更远。 MAE:模型离离群值较远,但离大多数其他数据点较近。 梯度下降法梯度下降法是一种数学技术,能够以迭代方式找出权重和偏差,从而生成损失最低的模型。梯度下降法会针对用户指定的多次迭代重复以下过程,以找到最佳权重和偏差。 数学上来说主要是求f(x)函数的导数(含多阶导数)找到最佳权重与偏差,导数>0,则导数曲线为凹函数,存在最小值。 逻辑回归(Logistic Regression)逻辑回归(Logistic Regression)是一种用于解决二分类问题的统计模...

预训练
预训练预训练是大模型的核心训练阶段,指利用海量无标注数据(如互联网文本、书籍、网页等)训练模型,使其语言学习的统计规律、语法结构及语义关联,形成通用语言理解能力。这一过程不针对具体任务,而是为模型奠定知识基础,例如GPT-3通过1750亿参数学习通用语言模式。 预训练原理传统AI模型依赖人工标注数据,成本高且泛化性差。预训练通过无监督学习从海量数据中自动提取语言规律,突破数据标注瓶颈。大模型参数规模(千亿至万亿级)使其能捕捉更复杂的语义关联,后续只需少量标注数据微调即可高效适配下游任务。 预训练实践案例GPT系列:通过网页、书籍等数据预训练,再微调实现对话、翻译等任务,如ChatGPT。华为盘古大模型:预训练后仅需行业少量数据精调,即可应用于气象预测、药物研发等领域。IDC报告案例:预训练模型在金融、医疗等场景中,通过“通用知识+小样本微调”降低成本并提升准确率。 总结预训练是大模型的“筑基”阶段,通过海量无标注数据学习通用语言知识;其价值在于降低标注依赖、提升泛化性;实际应用时需结合微调适配具体场景。